

Тест GPGPU



Эта тестовая панель, которую можно запустить из Tools | GPGPU Benchmark предлагает набор тестов OpenCL GPGPU. Они предназначены для измерения вычислительной производительности GPGPU с использованием различных рабочих нагрузок OpenCL. Каждый отдельный тест можно запустить на 16 графических процессорах, включая графические процессоры AMD, Intel и NVIDIA или их комбинацию. Разумеется, полностью поддерживаются конфигурации CrossFire и SLI, а также dGPU и APU. В настоящее время существует только предварительная поддержка конфигураций HSA. По сути, тестироваться будет любое вычислительное устройство, указанное как GPU среди устройств OpenCL.
Текущие тесты OpenCL не оптимизированы для какой-либо архитектуры GPU. Вместо этого модуль AIDA64 OpenCL использует компилятор OpenCL, который оптимизирует ядро OpenCL для лучшей работы на базовом оборудовании. Ядра OpenCL, используемые для этих тестов, компилируются в режиме реального времени с использованием драйвера OpenCL графического процессора. По этой причине всегда рекомендуется обновлять все видеодрайверы (Catalyst, ForceWare, HD Graphics и т. д.) до последней версии. Для компиляции передаются следующие параметры компилятора OpenCL: -cl-fast-relaxed-math -cl-mad-enable.
Для сравнения панель GPGPU Benchmark также предлагает измерения ЦП. Однако эталонные тесты ЦП не используют OpenCL, а записываются в собственном машинном коде x86/x64 с использованием доступных расширений набора инструкций, таких как SSE, AVX, AVX2, FMA и XOP. Эти тесты CPU очень похожи на старые тесты AIDA64 CPU и FPU, но на этот раз они измеряют максимальную вычислительную производительность (FLOPS, IOPS). Тесты ЦП в значительной степени многопоточные и оптимизированы для каждой архитектуры ЦП, появившейся со времен первого Pentium.
В настоящее время доступны следующие эталонные тесты:
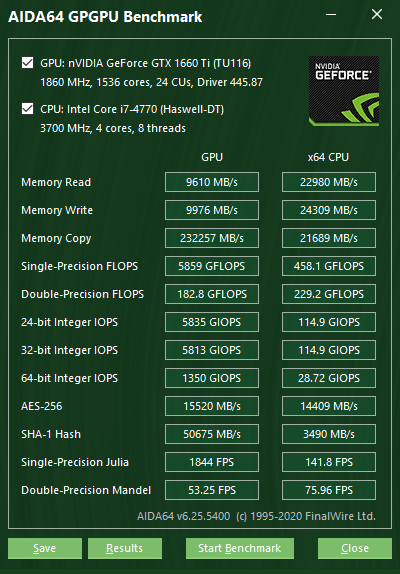
Memory Read
Измеряет пропускную способность между устройством GPU и ЦП, эффективно измеряя производительность графического процессора, может копировать данные из памяти собственного устройства в системную память. Его также называют пропускной способностью между устройствами и хостами. Эталонный тест ЦП измеряет пропускную способность чтения памяти, то есть скорость, с которой ЦП может считывать данные из системной памяти.
Запись в память
Измеряет пропускную способность между ЦП и Устройство GPU, эффективно измеряющее производительность, которую GPU может копировать данные из системной памяти в память своего устройства. Это также называется пропускной способностью хост-устройство. Эталонный тест ЦП измеряет пропускную способность записи в память, то есть скорость, с которой ЦП может записывать данные в системную память.
Копирование памяти
Эффективно измеряет производительность собственной памяти устройства графического процессора. измеряя производительность, которую GPU может копировать данные из своей собственной памяти устройства в другое место в той же памяти устройства. Его также называют пропускной способностью между устройствами. Эталонный тест ЦП измеряет пропускную способность копирования памяти, то есть скорость, с которой ЦП может перемещать данные в системной памяти из одного места в другое.
FLOPS с одинарной точностью
Измеряет MAD ( Multiply-Addition) производительность графического процессора, также известная как FLOPS (операций с плавающей запятой в секунду), с данными с плавающей запятой одинарной точности (32-разрядные, «с плавающей запятой»).
Double-Precision FLOPS
Измеряет производительность графического процессора MAD (Multiply-Addition), также известную как FLOPS (операций с плавающей запятой в секунду), с двойной точностью (64-разрядная, «двойная») с плавающей запятой. данные. Не все графические процессоры поддерживают операции с плавающей запятой двойной точности. Например, современные настольные и мобильные графические устройства Intel поддерживают только операции с плавающей запятой одинарной точности.
24-разрядное целое число операций ввода-вывода в секунду
Измеряет производительность MAD (умножение-сложение) Графический процессор, также известный как IOPS (целочисленные операции в секунду), с 24-битными целочисленными («int24») данными. Этот специальный тип данных определен в OpenCL, учитывая, что многие графические процессоры способны выполнять операции int24 в своих единицах с плавающей запятой, эффективно повышая производительность целочисленных операций в 3–5 раз по сравнению с 32-разрядными целочисленными операциями.
32-разрядное целое число операций ввода-вывода в секунду
Измеряет производительность графического процессора MAD (множественное сложение), также известную как IOPS (целочисленное число операций в секунду), с 32-разрядным целым числом ("int") данных. .
64-разрядное целочисленное число операций ввода-вывода в секунду
Измеряет производительность графического процессора MAD (умножение-сложение), также известную как IOPS (целочисленное число операций в секунду), с 64-разрядным целым числом ( "длинные") данные. Большинство графических процессоров не имеют выделенных ресурсов выполнения для 64-битных целочисленных операций. Такие устройства эмулируют 64-битные целочисленные операции на своих 32-битных целочисленных исполнительных устройствах. В таких случаях производительность 64-битных целых чисел может быть очень низкой.
AES-256
Мы можем использовать этот тест GPGPU на основе OpenCL для измерения производительности шифрования AES-256 современных графических процессоров и APU.
SHA-1
Мы можем использовать этот тест GPGPU на основе OpenCL для измерения производительности хеширования SHA-1 современных графических процессоров и APU.
Юлия с одинарной точностью
Мера s одинарная точность (32-разрядная, «с плавающей запятой») с плавающей запятой за счет вычисления нескольких кадров популярного фрактала «Джулия».
Мандель с двойной точностью
Меры двойная точность (64-битная, «двойная») производительность с плавающей запятой за счет вычисления нескольких кадров популярного фрактала «Мандельброта». Не все графические процессоры поддерживают операции с плавающей запятой двойной точности. Например, современные настольные и мобильные графические устройства Intel поддерживают только операции с плавающей запятой одинарной точности.
Пользовательский интерфейс
Вы можете использовать флажки, чтобы выбрать устройство GPU или ЦП для ориентиры. Состояние флажка ЦП будет сохранено после закрытия панели.
Вы можете запустить тесты для выбранных устройств, нажав кнопку «Начать тест». Если вы хотите запустить все тесты, но только на графических процессорах, вам нужно дважды щелкнуть метку столбца графического процессора. Если вы хотите запустить только тесты чтения памяти как на графическом процессоре, так и на процессоре, вам нужно дважды щелкнуть метку чтения памяти. Если вы хотите запустить тест чтения памяти только на графических процессорах, вам нужно дважды щелкнуть ячейку, в которой после завершения теста появится запрошенный результат теста.
Тестирование выполняется одновременно на всех выбранных графических процессорах с использованием нескольких потоков и нескольких контекстов OpenCL. , каждый с одной очередью команд. Однако тесты процессора запускаются только после завершения тестов графического процессора. В настоящее время одновременное выполнение тестов графического процессора и процессора невозможно.
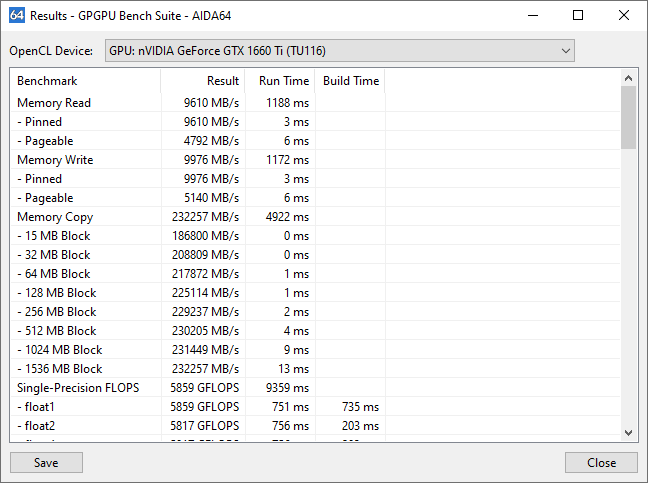
Если в системе несколько графических процессоров, в первом столбце результатов будет отображаться совокупная оценка для всех графических процессоров. Отдельные результаты графического процессора объединяются (суммируются), и метка столбца будет выглядеть, например, как «4 графических процессора». Если вы хотите проверить отдельные результаты, вы можете либо проверить только один графический процессор, либо нажать кнопку «Результаты», чтобы открыть окно результатов.
Если у вас два устройства с графическим процессором и вы отключили центральный процессор test, сняв соответствующий флажок, панель переключится в режим работы с двумя GPU, где первый столбец используется для отображения результатов для GPU1, а второй — для GPU2. Если вы хотите увидеть общую производительность обоих графических процессоров, просто снова установите флажок ЦП после завершения теста, и интерфейс вернется к макету по умолчанию.